目录
因为实验室假期需要写一篇关于opencv的作业 所以顺便看了一下opencv(版本3.2.0)里面关于高斯模糊的源码
分析函数接口
首先,在下用的是vs版本的opencv,是直接编译好给你静态库(.lib)文件的,所以当我按住ctrl寻找GaussianBlur这个函数时 只发现了其在imgproc.hpp里面提供给你的接口。
大概是下面这个样子的:
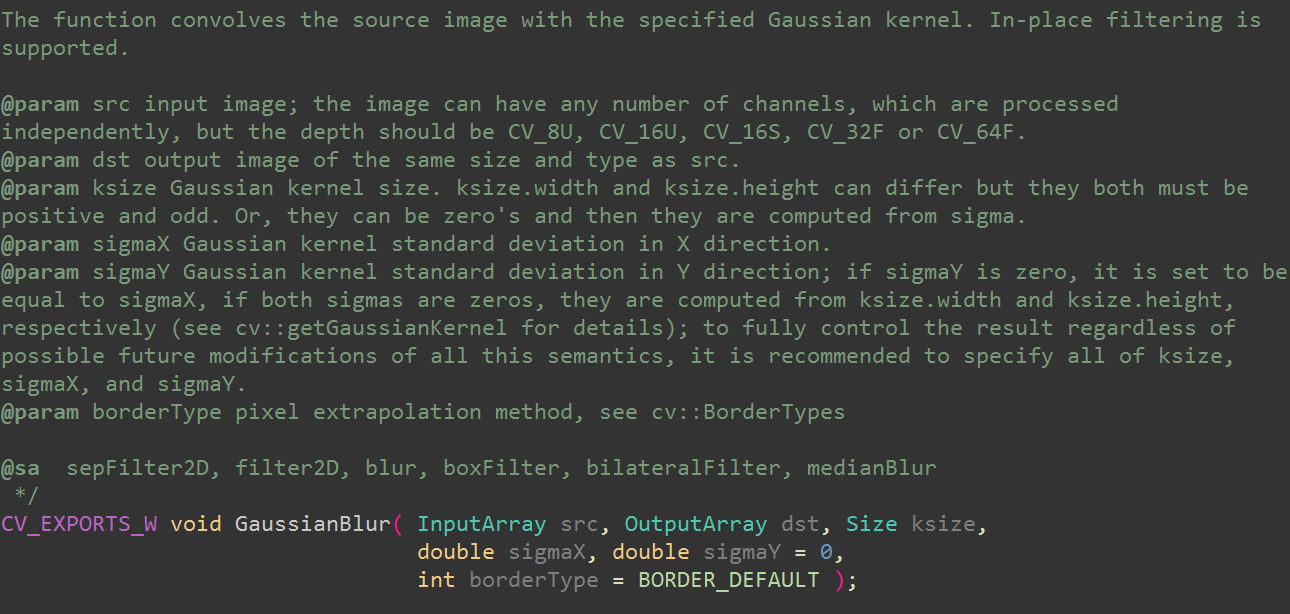

该函数将源图像与指定的卷积核进行卷积。并且支持原图像直接进行滤波操作。
可以看到这个函数接口主要由四个部分组成:
-
CV_EXPORTS_W
继续往上找 可以发现这是一个宏定义
可以发现 这个宏定义是在编译阶段将
CV_EXPORTS替换为了CV_EXPORTS_W再向上查找 会发现
这里又是一个宏组成的用以定义
CV_EXPORTS的宏组,这一段其实就是类似于if else的结构,主要的作用机理便是适配各类环境(操作系统) 。从中,我们这里又分成了三个部分进行解析:#if (defined WIN32 || defined _WIN32 || defined WINCE || defined __CYGWIN__) && defined CVAPI_EXPORTS
可以看到,这里判断了两个表达式的逻辑与((defined WIN32 || defined _WIN32 || defined WINCE || defined __CYGWIN__)和defined CVAPI_EXPORTS)-
首先,
defined的意义在于寻找后面的字段是否已经被宏定义过。 -
其次,观察第一个表达式,发现
_WIN32在之前已经被定义过了,通过查阅微软官方宏定义文档发现这个字段作用是基于编译器一个信号,表明是Windows环境下编译及运行的程序。
再查找前后未定义过的字段,继而发现
WIN32是只要包含了 Windows.h,那么 WIN32 常量是肯定定义了的设定,不能用于判断平台环境。
而WINCE便是判断是否为WINCE环境的程序__CYGWIN__如果事先有了解过cygwin这个程序的话,这个应该不难看懂,也是用以判断环境的定义,而cywin则是在Windows环境下用以模拟Unix环境的软件(P.S.还是蛮好用的) -
再次,观察第二个表达式,也是查找字段是否定义过,这个查了一下,发现这个宏定义是存在于opencv.dll这个文件里面的。也就是判断是否已经链接了动态库。
-
这样这一行便很容易懂了,目的便是判断程序环境是否为Windows且已经链接opencv.dll的库用以进行下一步操作。
-
再提一句,关于这个操作系统(环境)的判定其实还有很多,这里放一个Qt里面关于系统判定的头文件(147行开始)(版本比较老了 可自行再自己qt里查看)
-
# define CV_EXPORTS __declspec(dllexport)
这一句涉及到的主要是dll函数导入,需要和下面最后三行联合起来看#define CV_EXPORTS
第二行需要联合上面这句一同分析,首先,这个头文件内部写的都是接口,都是作者自己编写留给别人用以调用的,并且从第一点分析的结果来看,这些接口的实现都是放在opencv.dll文件中的,而第一行的判断便是判断你是否在最需要隐式调用,如果有,那么直接可以利用隐式调用的方法进行函数导出(具体__declspec也有在微软文档里写)
反之,如果判断事先未进行链接,那么使用的时候必然是显式调用(没错,就是配置环境的时候配置的lib文件链接,那就是显式调用了参考此篇文章),既然是显式调用,自然便不需要进行函数导出操作。所以将CV_EXPORTS字段设置为空。elif defined __GNUC__ && __GNUC__ >= 4define CV_EXPORTS __attribute__((visibility("default")))
这两句涉及的主要有两个功能: 1. 判断是否为GCC编译环境 2. 为全局动态库函数设置非隐藏声明
对于第一点,类似于分析第一条,可以知道这句的意思便是检查gcc并测试是否高于4.0.0版本(猜测与c++标准有关)
-
void
函数返回值,这里返回值为空 -
GaussianBlur
函数名,这里因为是声明所以是跟源码的函数一样,可以很快找到源码定义。 -
()
括号里面的是函数参数根据上面的说明注释,便可解读出这个函数所有参数意义:src这是输入图像,这个图像可以拥有任意数量的通道,这些通道是独立处理的,但深度应该是CV_8U,CV_16U,CV_16S,CV_32F或CV_64F。dst这是输出图像,大小与类型与src相同。ksize这是卷积核的大小参数(是数字desu)。其中ksize.width和ksize.height可以不同,但是它们必须是一个正奇数(或者零),并且您不用担心卷积核内部参数问题,卷积核会根据sigma来计算。sigmaXX方向的卷积核标准偏差。sigmaYY方向的高斯核标准偏差; 如果sigmaY为零,则设置为等于sigmaX,如果两个sigma都是零,则它们是从ksize.width和ksize.height计算的(详见cv :: getGaussianKernel); 这些语义未来均有可能修改,建议指定所有ksize,sigmaX和sigmaY。borderType像素外推模式,请参阅cv :: BorderTypessepFilter2D, filter2D, blur, boxFilter, bilateralFilter, medianBlur。这里显示了函数的相关函数,是观察源码的重要提示
这样,对于函数接口的解析就算是完成了,从中我们可以得出以下几个结论:
- 直接ctrl寻找到底是不能找到原函数代码的。
- 找到原函数的同时也需要sepFilter2D, filter2D, blur, boxFilter, bilateralFilter, medianBlur这一些列函数辅助理解。
- 这个函数在cv命名空间中,名称应该为
cv::GaussianBlur。
所以接下来第一步便是需要在源码中寻找到真正的函数实现。
源码解析
理解高斯模糊函数
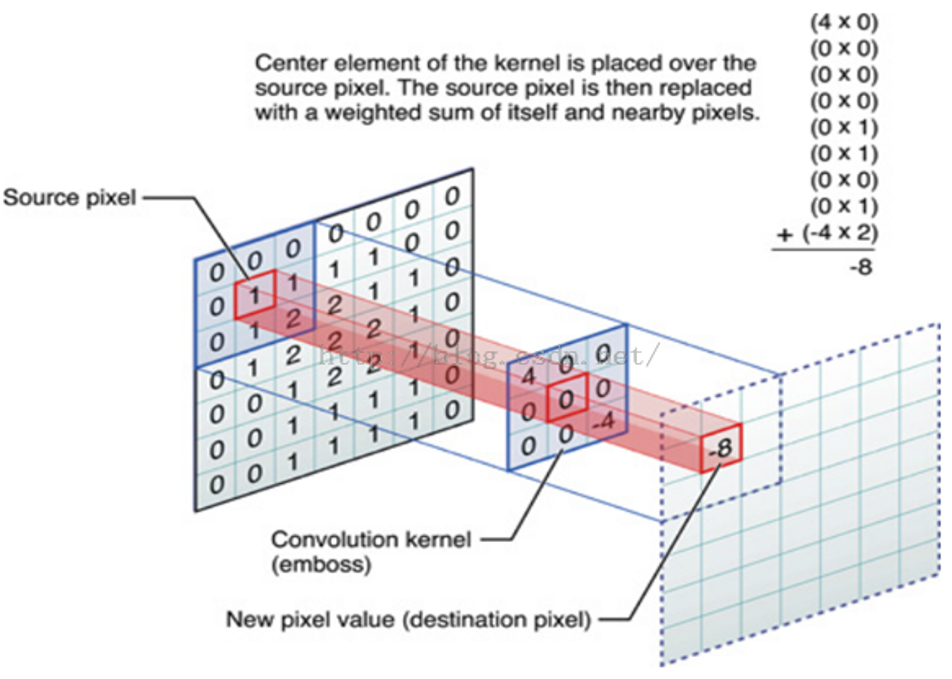
高斯模糊函数本质是利用高斯滤波器对于给定图像进行平滑操作。平滑操作时什么,是减少噪点。噪点的原因又是什么,是单个像素包含的信息过于独立。如何减少噪点,很简单,只需要让每个像素点包含有周围像素的部分信息就行了呗。选用什么方法,最简单的方法便是——卷积(见下图)。利用一个给定的以某种分布函数构建的二维卷积内核,将中心点对准像素点,进行卷积操作,得到的像素点便包含了周围像素的不完全信息,这样子附近的像素点差异性便会越来越小,当整张图像(或选中部分)卷积完成后,每个像素点便不再过于独立,每个便有了附近像素点的信息,这样字图像便不会看上去那么的“扎眼”,会温润平滑许多,这就是高斯模糊的本质了。
查找函数
利用grep命令,很容易便能找到这个函数,找到文件并切到这个函数定义,便可以窥见整个函数的全貌了。
以下是cv::GaussianBlur函数全貌:
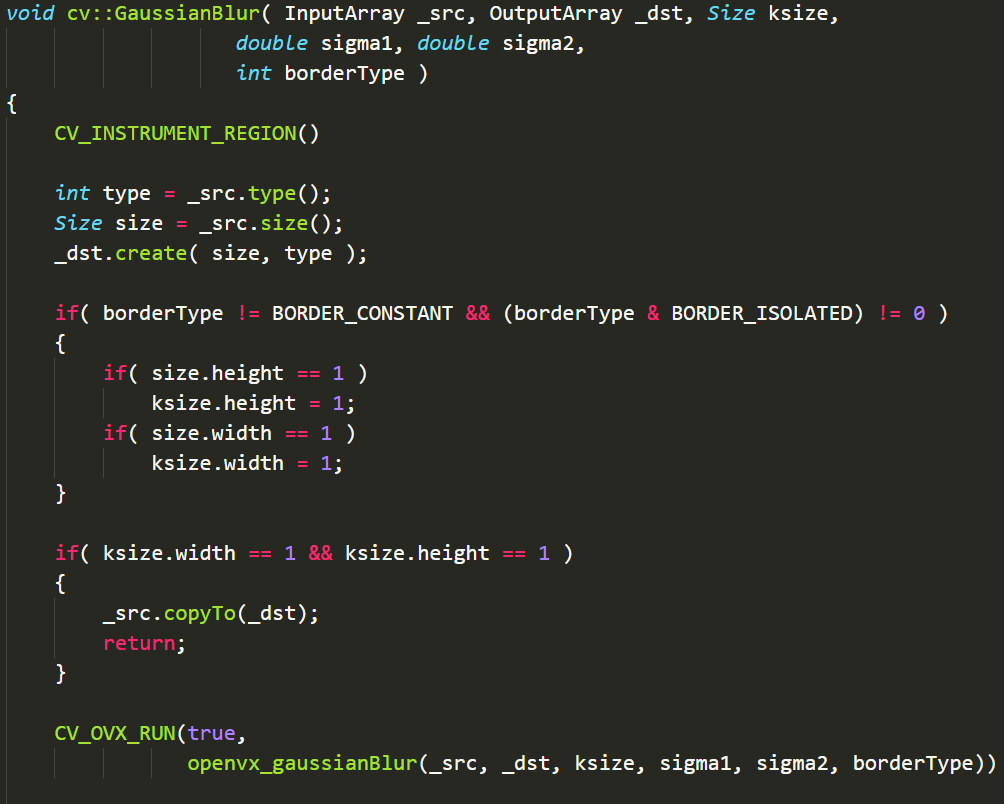
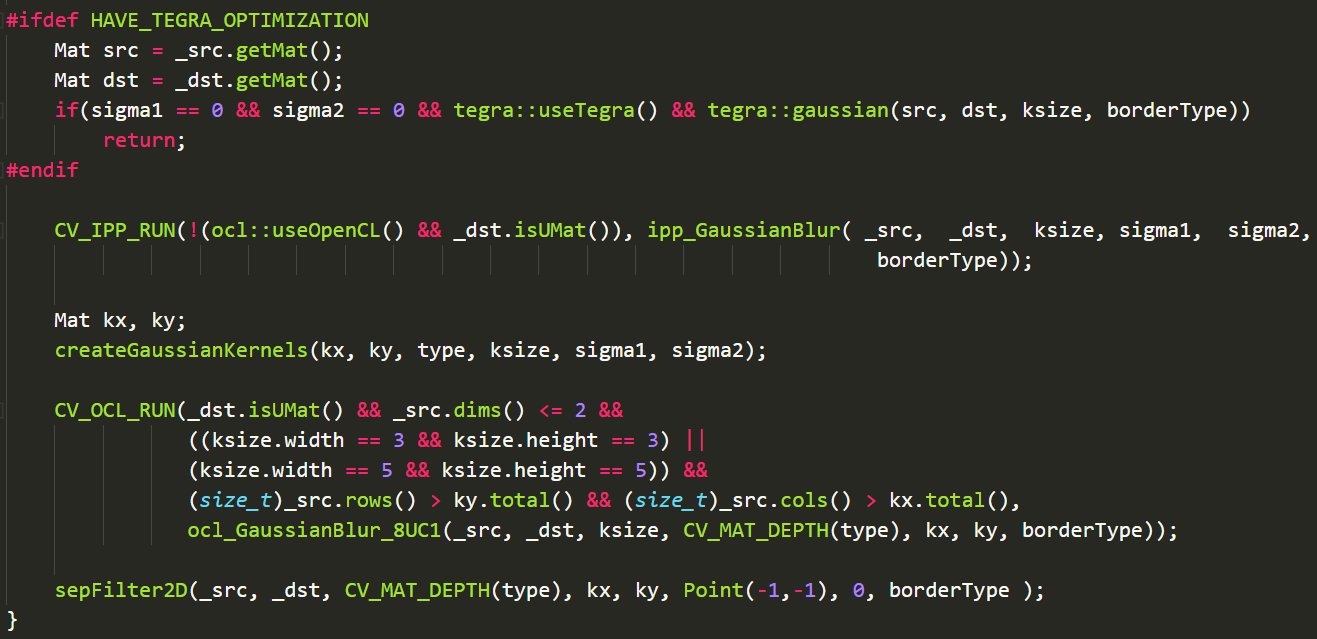
分析函数
分析这个函数之前,首先先要从内部关联的函数看起。
CV_INSTRUMENT_REGION()
这一行末尾没有分号,这样的类似函数的字符段有很大可能是一个宏定义变量,经查找,在private.hpp文件中有以下定义:
///// General instrumentation // General OpenCV region instrumentation macro #define CV_INSTRUMENT_REGION() CV_INSTRUMENT_REGION_META(cv::instr::TYPE_GENERAL, cv::instr::IMPL_PLAIN)
经查找,这个字段主要是关于初始化以及边界类型的判断。
if( borderType != BORDER_CONSTANT && (borderType & BORDER_ISOLATED) != 0 )
c++int type = _src.type();
Size size = _src.size();
_dst.create( size, type );
/**
根据说明文档中所写的
BORDER_CONSTANT = 0, //!< `iiiiii|abcdefgh|iiiiiii`with some specified `i`
BORDER_REPLICATE = 1, //!< `aaaaaa|abcdefgh|hhhhhhh`
BORDER_REFLECT = 2, //!< `fedcba|abcdefgh|hgfedcb`
BORDER_WRAP = 3, //!< `cdefgh|abcdefgh|abcdefg`
BORDER_REFLECT_101 = 4, //!< `gfedcb|abcdefgh|gfedcba`
BORDER_TRANSPARENT = 5, //!< `uvwxyz|absdefgh|ijklmno`
BORDER_REFLECT101 = BORDER_REFLECT_101, //!< same as BORDER_REFLECT_101
BORDER_DEFAULT = BORDER_REFLECT_101, //!< same as BORDER_REFLECT_101
BORDER_ISOLATED = 16 //!< do not look outside of ROI
BORDER_CONSTANT 需要设置borderValue 指定 ' i ' 值(常数)
BORDER_REPLICATE ,复制边界像素
BORDER_REFLECT ,反射复制边界像素
BORDER_REFLECT_101,以边界为对称轴反射复制像素
*/
/*
这里是说如果边缘扩展不是常数扩展,且在规定图像范围内部,便执行下列操作
*/
if( borderType != BORDER_CONSTANT && (borderType & BORDER_ISOLATED) != 0 )
{
// 如果输入矩阵是一个行向量,则滤波核的高强制为1
// 下面同理
if( size.height == 1 )
ksize.height = 1;
if( size.width == 1 )
ksize.width = 1;
}
// 如果核宽跟核高都是一直接复制输出
if( ksize.width == 1 && ksize.height == 1 )
{
_src.copyTo(_dst);
return;
}
CV_OVX_RUN(true, openvx_gaussianBlur(_src, _dst, ksize, sigma1, sigma2, borderType))
这里很明显是一个被宏定义的字段,通过查找,我们能够找到其定位在modules/core/include/opencv2/core/openvx/ovx_defs.hpp当中
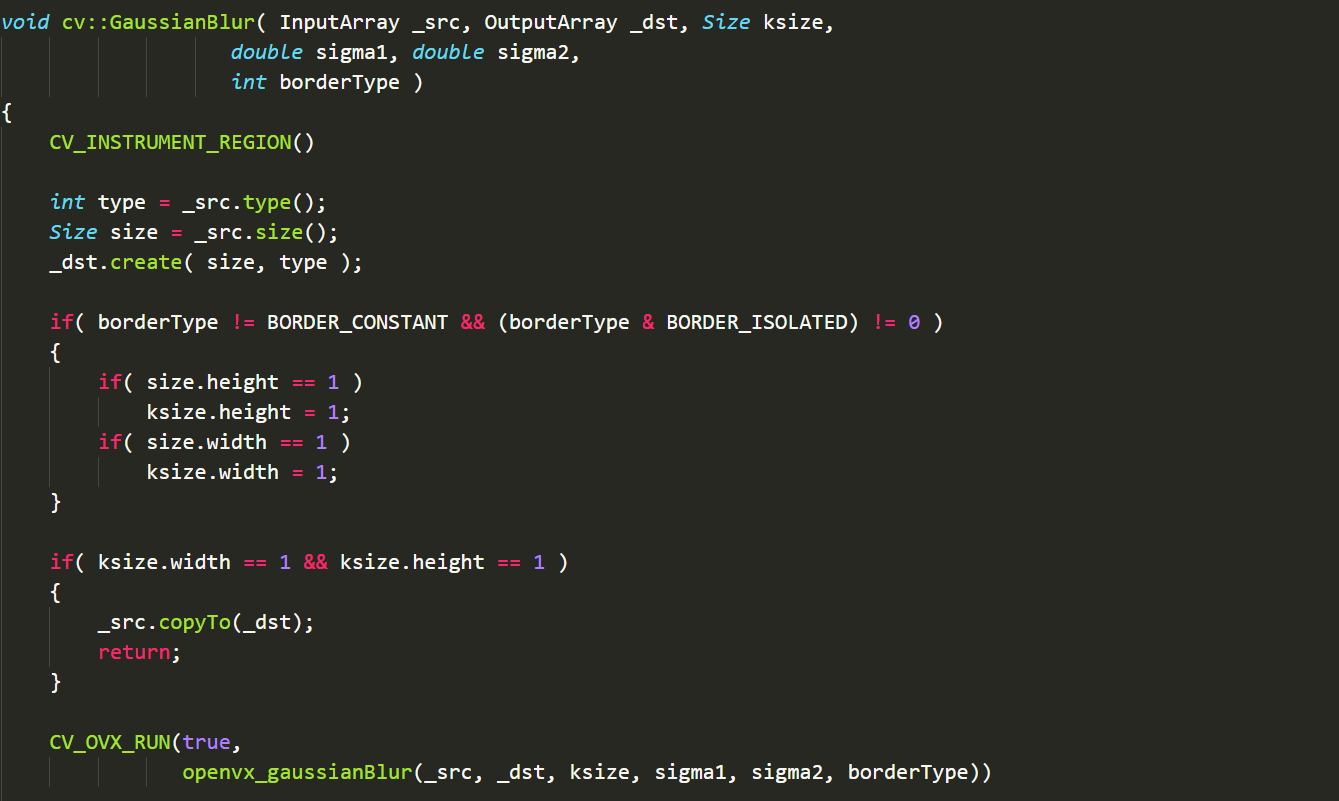
按每行解析的话就是如下:
c++// 用于检测基于OpenVX的实现的实用程序宏
#ifdef HAVE_OPENVX
// 如果检测到OPENVX便执行下列语句
// 下面这两句主要作用也是标识
#define IVX_HIDE_INFO_WARNINGS // 隐藏警告信息
#define IVX_USE_OPENCV // 使用opencv的标识
#include "ivx.hpp" // 将hpp文件包含进来
#define CV_OVX_RUN(condition, func, ...) \ // ...会被替换
// 这里为了给外界提供OpenVX使用表示 利用宏定义做成了一个接口
// 而这个接口则是主要为了提供硬件层面加速用的(主要面向对象是嵌入式设计)
if (cv::useOpenVX() && (condition) && func) \
{ \
// __VA_ARGS__是可变参数宏定义 用以替换上面...的内容
return __VA_ARGS__; \
}
#else
// 否则便执行下面这条
#define CV_OVX_RUN(condition, func, ...)
#endif // HAVE_OPENVX
其中useOpenVX()函数主要是返回一个bool类型的变量用以判断是否使用openVX用以计算。
所以CV_OVX_RUN()这句话便是对于嵌入式设计进行尝试性的优化操作。
ifdef至endif部分
c++//若之前有过HAVE_TEGRA_OPTIMIZATION优化选项的定义,则执行宏体中的tegra优化版函数并返回
#ifdef HAVE_TEGRA_OPTIMIZATION
// 拷贝到临时变量(暂不知为什么要拷贝到一个临时变量里面去)
Mat src = _src.getMat();
Mat dst = _dst.getMat();
if(sigma1 == 0 && sigma2 == 0 && tegra::useTegra() && tegra::gaussian(src, dst, ksize, borderType))
return;
#endif
这里也显而易见是尝试tegra优化。
但是为什么拷贝到临时变量里也可以改变原值,这里需要进一步到Mat变量的运算符重载里面进行参考。
C++inline
Mat& Mat::operator = (const Mat& m)
{
if( this != &m )
{
if( m.u )
CV_XADD(&m.u->refcount, 1);
release(); // 归零初始化
/**
归零后进行基本数据共享
*/
flags = m.flags;
if( dims <= 2 && m.dims <= 2 )
{
dims = m.dims;
rows = m.rows;
cols = m.cols;
step[0] = m.step[0];
step[1] = m.step[1];
}
else
copySize(m);
data = m.data;
datastart = m.datastart; // 共享数据头
dataend = m.dataend; // 共享数据尾
datalimit = m.datalimit;
allocator = m.allocator; // 内存共享
u = m.u;
}
return *this; // 返回当前对象的引用
}
我们可以发现在=重载的时候仅是进行的浅拷贝操作,意思是只将数据头数据尾进行复制,而所有数据的内存数据都是相通共享的。固仅需要一方变量更改便会联动所有对其进行过浅拷贝的变量变化。
剩下部分
c++/**
这里主要是针对opencl(GPU加速)无法使用的情况进行CPU版本计算
这个IPP是一个Intel提供的开源的计算机视觉加速库,可以提供很多算法的Intel专属的多线程优化方案API,这也是为什么下面在opencl的gpu优化代码之后还又添加了利用CPU版本的filter2D的计算方案(因为有部分Intel专属的优化函数,针对APU和老式的Intel CPU(09年之前)无法进行计算,所以只能选取最普通的filter2D计算方案执行)
官网FAQ(有兴趣可以了解一下): https://software.intel.com/en-us/articles/intel-integrated-performance-primitives-intel-ipp-open-source-computer-vision-library-opencv-faq/
*/
CV_IPP_RUN(!(ocl::useOpenCL() && _dst.isUMat()), ipp_GaussianBlur( _src, _dst, ksize, sigma1, sigma2, borderType));
Mat kx, ky;
/**
这里是新建一个高斯卷积内核(后面讲)
*/
createGaussianKernels(kx, ky, type, ksize, sigma1, sigma2);
/**
这里是针对ksize = 3 or 5的情况做了opencl优化(A卡N卡均可享受opencl优化qwq)
*/
CV_OCL_RUN(_dst.isUMat() && _src.dims() <= 2 &&
((ksize.width == 3 && ksize.height == 3) ||
(ksize.width == 5 && ksize.height == 5)) &&
(size_t)_src.rows() > ky.total() && (size_t)_src.cols() > kx.total(),
ocl_GaussianBlur_8UC1(_src, _dst, ksize, CV_MAT_DEPTH(type), kx, ky, borderType));
/**
这里便是利用filter2D进行操作了
传入Point(-1, -1) 是指内核中的锚点(就是后面的anchor)位置。默认值(-1,-1)表示锚点位于内核中心。
0 则是存储单位 默认是0 后面会通过计算改变并存储
*/
sepFilter2D(_src, _dst, CV_MAT_DEPTH(type), kx, ky, Point(-1,-1), 0, borderType);
这里在下主要解析createGaussianKernels与sepFilter2D这两个函数,主要是因为无论是openvx_gaussianBlur还是ipp_GaussianBlur以及ocl_GaussianBlur_8UC1都有着大量未知的API,要读懂这些API还需要大量文档查阅,在下在此就先不解析了。
所以首先先来看一下createGaussianKernels这个函数:
c++/**
这个函数仅是用于是创建高斯卷积核
*/
static void createGaussianKernels( Mat & kx, Mat & ky, int type, Size ksize,
double sigma1, double sigma2 )
{
int depth = CV_MAT_DEPTH(type); // 根据输入图像类型获得位深度
if( sigma2 <= 0 )
sigma2 = sigma1; // 非正则与sigma1相同
// 从sigma自动检测内核大小(如果用户没有设置ksize的话)
// 根据CV_8U来计算 大致接近7*sigma 或者 9*sigma
// cvRound函数还内联了汇编 在下看不懂了
// |1 的原因是使宽高为奇数
if( ksize.width <= 0 && sigma1 > 0 )
ksize.width = cvRound(sigma1*(depth == CV_8U ? 3 : 4)*2 + 1)|1;
if( ksize.height <= 0 && sigma2 > 0 )
ksize.height = cvRound(sigma2*(depth == CV_8U ? 3 : 4)*2 + 1)|1;
// 这句只是为了保证卷积核的宽跟高是正奇数
CV_Assert( ksize.width > 0 && ksize.width % 2 == 1 &&
ksize.height > 0 && ksize.height % 2 == 1 );
// 取最大
sigma1 = std::max( sigma1, 0. );
sigma2 = std::max( sigma2, 0. );
kx = getGaussianKernel( ksize.width, sigma1, std::max(depth, CV_32F) );
if( ksize.height == ksize.width && std::abs(sigma1 - sigma2) < DBL_EPSILON )
// 这里 如果判断核高与核宽相等,且sigma相差很小的情况下
// 便可以直接进行赋值操作,减少了计算量
ky = kx;
else
ky = getGaussianKernel( ksize.height, sigma2, std::max(depth, CV_32F) );
}
从中我们还需要解析getGaussianKernel这个函数:
c++cv::Mat cv::getGaussianKernel( int n, double sigma, int ktype )
{
// 这里定义了一个常量用以规定大小
const int SMALL_GAUSSIAN_SIZE = 7;
// 一个4 * 7的矩阵,用于对奇数长度小内核进行优化计算
static const float small_gaussian_tab[][SMALL_GAUSSIAN_SIZE] =
{
{1.f},
{0.25f, 0.5f, 0.25f},
{0.0625f, 0.25f, 0.375f, 0.25f, 0.0625f},
{0.03125f, 0.109375f, 0.21875f, 0.28125f, 0.21875f, 0.109375f, 0.03125f}
};
/**
这里计算滤波系数(数组)
如果 内核尺寸为奇数 且小于7
并且sigma小于等于0
那么滤波系数便是根据上面的small_gaussian_tab决定的
否则便是0
*/
const float* fixed_kernel = n % 2 == 1 && n <= SMALL_GAUSSIAN_SIZE && sigma <= 0 ? small_gaussian_tab[n>>1] : 0;
/**
检测数据类型是否为float和double
*/
CV_Assert( ktype == CV_32F || ktype == CV_64F );
Mat kernel(n, 1, ktype); // 建立一维向量
// 定义指针指向数据
float* cf = kernel.ptr<float>();
double* cd = kernel.ptr<double>();
// 当sigma小于0时,采用公式得到sigma(只与n有关),大于0就可以直接使用了。
double sigmaX = sigma > 0 ? sigma : ((n-1)*0.5 - 1)*0.3 + 0.8;
// 表达式中e指数要用到
double scale2X = -0.5/(sigmaX*sigmaX);
double sum = 0;
int i;
for( i = 0; i < n; i++ )
{
double x = i - (n-1)*0.5;
// 根据上面计算出来的系数来决定是否重新计算值
double t = fixed_kernel ? (double)fixed_kernel[i]:std::exp(scale2X*x*x);
//根据精度选择变量
if( ktype == CV_32F )
{
cf[i] = (float)t;
sum += cf[i];
}
else
{
cd[i] = t;
sum += cd[i];
}
}
sum = 1./sum; // 归一化操作,计算需要除的数值
for( i = 0; i < n; i++ )
{
if( ktype == CV_32F )
cf[i] = (float)(cf[i]*sum);
else
cd[i] *= sum;
}
return kernel; // 返回建立好的一维内核
}
这两个函数的主要目的就是计算出高斯卷积核,这里选用分离计算,就是先计算水平(x)方向的一维卷积核,再根据sigma判断是否重新计算垂直(y)方向的一维卷积内核,这样子分离计算再针对尺寸较大的滤波器也可以有很高的效率,并且分离计算结合多线程也是很好的选择。
看完高斯内核的建立,我们知道高斯模糊主要利用了分离计算,那最后sepFilter2D函数也很容易看懂了:
c++void cv::sepFilter2D( InputArray _src, OutputArray _dst, int ddepth,
InputArray _kernelX, InputArray _kernelY, Point anchor,
double delta, int borderType )
{
CV_INSTRUMENT_REGION()
/*
这里考虑如果输入函数是UMat形式且维度小于等于2的情况下
优先考虑使用opencl优化过的filter2D计算
*/
CV_OCL_RUN(_dst.isUMat() && _src.dims() <= 2
&& (size_t)_src.rows() > _kernelY.total()
&& (size_t)_src.cols() > _kernelX.total(),
ocl_sepFilter2D(_src, _dst, ddepth, _kernelX, _kernelY, anchor, delta, borderType))
Mat src = _src.getMat(),
kernelX = _kernelX.getMat(),
kernelY = _kernelY.getMat();
if( ddepth < 0 )
ddepth = src.depth();
_dst.create( src.size(), CV_MAKETYPE(ddepth, src.channels()) );
Mat dst = _dst.getMat();
/*
找到src的矩阵的矩阵头存入wsz当中,并且将偏移量存入ofs变量中
这两个变量用于快速读取全部图像
*/
Point ofs;
Size wsz(src.cols, src.rows);
if( (borderType & BORDER_ISOLATED) == 0 )
src.locateROI( wsz, ofs );
/*
进行预先检测内核是否有误
*/
CV_Assert( kernelX.type() == kernelY.type() &&
(kernelX.cols == 1 || kernelX.rows == 1) &&
(kernelY.cols == 1 || kernelY.rows == 1) );
Mat contKernelX = kernelX.isContinuous() ? kernelX : kernelX.clone();
Mat contKernelY = kernelY.isContinuous() ? kernelY : kernelY.clone();
/*
生成一个二维滤波(filter2D)引擎
*/
Ptr<hal::SepFilter2D> c = hal::SepFilter2D::create(
src.type(), dst.type(), kernelX.type(),
contKernelX.data,
kernelX.cols + kernelX.rows - 1,
contKernelY.data,
kernelY.cols + kernelY.rows - 1,
anchor.x,
anchor.y,
delta,
borderType & ~BORDER_ISOLATED);
/*
调用这个引擎
*/
c->apply(src.data, src.step, dst.data, dst.step, dst.cols, dst.rows, wsz.width, wsz.height, ofs.x, ofs.y);
}
剩下的便是寻找到这个引擎跟调用函数的实现了。
c++/*
Ptr类似于boost::shared_ptr,它是Boost库的一部分
(http://www.boost.org/doc/libs/release/libs/smart_ptr/shared_ptr.htm)
和 std::shared_ptr[C ++ 11标准](http://en.wikipedia.org/wiki/C++11)
P.S.其实大部分c++11标准都是boost库里面抄过来的
*/
Ptr<SepFilter2D> SepFilter2D::create(int stype, int dtype, int ktype,
uchar * kernelx_data, int kernelx_len,
uchar * kernely_data, int kernely_len,
int anchor_x, int anchor_y, double delta, int borderType)
{
{
ReplacementSepFilter * impl = new ReplacementSepFilter();
if (impl->init(stype, dtype, ktype,
kernelx_data, kernelx_len,
kernely_data, kernely_len,
anchor_x, anchor_y, delta, borderType))
{
return Ptr<hal::SepFilter2D>(impl);
}
delete impl;
}
{
OcvSepFilter * impl = new OcvSepFilter();
impl->init(stype, dtype, ktype,
kernelx_data, kernelx_len,
kernely_data, kernely_len,
anchor_x, anchor_y, delta, borderType);
return Ptr<hal::SepFilter2D>(impl);
}
}
经查找,SepFilter2D是一个结构体,内含有上面的create函数以及两个虚函数(apply与析构函数),这就说明对于不同的impl有着不同的apply跟init。
然后,从ReplacementSepFilter的函数开始看起:
c++/**
这个结构体继承自SepFilter2D
具体作用便是使用hal api进行优化加速计算
是一个关于移动和嵌入式设计的库
*/
struct ReplacementSepFilter : public hal::SepFilter2D
{
/**
这里的cvhalFilter2D是一个结构体
其目的就是作为context变量使用(ctx 便是context简写)
*/
cvhalFilter2D *ctx;
bool isInitialized;
/**
委托构造函数 委托了两个构造函数进行构造
一个是定义了context为0,另一个则是定义了isInitialized为否
关于context(上下文)这个概念可以百度一下
在下是看的这篇:
https://wanderinghorse.net/computing/papers/context_types.html
*/
ReplacementSepFilter() : ctx(0), isInitialized(false) {}
/**
初始化函数
*/
bool init(int stype, int dtype, int ktype,
uchar * kernelx_data, int kernelx_len,
uchar * kernely_data, int kernely_len,
int anchor_x, int anchor_y, double delta, int borderType)
{
// 这里返回的值根据是否初始化成功赋值的
int res = cv_hal_sepFilterInit(&ctx, stype, dtype, ktype,
kernelx_data, kernelx_len,
kernely_data, kernely_len,
anchor_x, anchor_y, delta, borderType);
// 这里首先判断res是否与CV_HAL_ERROR_OK(0)相等
// 如果不相等便将0赋值给isInitialized
// 否则便是将1赋值
isInitialized = (res == CV_HAL_ERROR_OK);
return isInitialized;
}
/**
这个是ReplacementSepFilter的执行函数
*/
void apply(uchar* src_data, size_t src_step, uchar* dst_data, size_t
dst_step, int width, int height, int full_width, int full_height,
int offset_x, int offset_y)
{
if (isInitialized)
{
// 这里是调用并返回是否成功的结果
int res = cv_hal_sepFilter(ctx, src_data, src_step, dst_data,
dst_step, width, height, full_width,
full_height, offset_x, offset_y);
// 判断res是否与CV_HAL_ERROR_OK(0)不等
// 如果不等便无法调用
// 进入错误选项跳出滤波器
if (res != CV_HAL_ERROR_OK)
CV_Error(Error::StsNotImplemented, "Failed to run HAL sepFilter implementation");
}
}
/**
这里的析构函数在本篇不解析
*/
~ReplacementSepFilter()
{
if (isInitialized)
{
int res = cv_hal_sepFilterFree(ctx);
if (res != CV_HAL_ERROR_OK)
CV_Error(Error::StsNotImplemented, "Failed to run HAL sepFilter implementation");
}
}
};
在接下来便是OcvSepFilter函数:
c++struct OcvSepFilter : public hal::SepFilter2D
{
/**
建立一个滤波引擎 f
*/
Ptr<FilterEngine> f;
int src_type;
int dst_type;
bool init(int stype, int dtype, int ktype,
uchar * kernelx_data, int kernelx_len,
uchar * kernely_data, int kernely_len,
int anchor_x, int anchor_y, double delta, int borderType)
{
src_type = stype;
dst_type = dtype;
/**
分离卷积所以建立了X与Y的卷积内核
*/
Mat kernelX(Size(kernelx_len, 1), ktype, kernelx_data);
Mat kernelY(Size(kernely_len, 1), ktype, kernely_data);
/**
创建一个创建可分离的线性滤波器
*/
f = createSeparableLinearFilter( stype, dtype, kernelX, kernelY,
Point(anchor_x, anchor_y),
delta, borderType & ~BORDER_ISOLATED );
return true;
}
void apply(uchar* src_data, size_t src_step, uchar* dst_data, size_t
dst_step, nt width, int height, int full_width, int full_height,
int offset_x, int offset_y)
{
Mat src(Size(width, height), src_type, src_data, src_step);
Mat dst(Size(width, height), dst_type, dst_data, dst_step);
// 因为Ptr将模板设置为了FilterEngine,所以这里apply调用的是FilterEngine的启动函数
f->apply(src, dst, Size(full_width, full_height), Point(offset_x,
offset_y));
}
};
然后便是分析createSeparableLinearFilter 这个函数:
c++/**
可以看到其返回的是是一个引擎,
所以里面肯定是有横向与纵向线性滤波器了(所以才使用可分离的qwq)
*/
cv::Ptr<cv::FilterEngine> cv::createSeparableLinearFilter(
int _srcType, int _dstType,
InputArray __rowKernel, InputArray __columnKernel,
Point _anchor, double _delta,
int _rowBorderType, int _columnBorderType,
const Scalar& _borderValue )
{
// 定义变量
Mat _rowKernel = __rowKernel.getMat(),
_columnKernel = __columnKernel.getMat();
// 求矩阵的数组类型,数据类型包过通道数,深度,和据类型3种
_srcType = CV_MAT_TYPE(_srcType);
_dstType = CV_MAT_TYPE(_dstType);
// 求深度(输入输出都求)
int sdepth = CV_MAT_DEPTH(_srcType),
ddepth = CV_MAT_DEPTH(_dstType);
// 求输入矩阵的通道数并判断输入矩阵是否与输出矩阵通道数相等
int cn = CV_MAT_CN(_srcType);
CV_Assert( cn == CV_MAT_CN(_dstType) );
// rowsize
int rsize = _rowKernel.rows + _rowKernel.cols - 1;
// columnsize
int csize = _columnKernel.rows + _columnKernel.cols - 1;
// 如果内核锚点是负数,则从中心点开始进行
if( _anchor.x < 0 )
_anchor.x = rsize/2;
if( _anchor.y < 0 )
_anchor.y = csize/2;
/**
获得内核的类型
大致分为五种:
KERNEL_GENERAL 通用内核 无任何对称性或其他属性
KERNEL_SYMMETRICAL kernel[i] == kernel[ksize-i-1] (系数对称),且锚点位于中心
KERNEL_ASYMMETRICAL kernel[i] == -kernel[ksize-i-1] (系数相反对称),锚点同上
KERNEL_SMOOTH 所有内核元素都是非负的并且总和为1
KERNEL_INTEGER 所有内核系数都是整数
*/
int rtype = getKernelType(_rowKernel,
_rowKernel.rows == 1 ? Point(_anchor.x, 0) : Point(0, _anchor.x));
int ctype = getKernelType(_columnKernel,
_columnKernel.rows == 1 ? Point(_anchor.y, 0) : Point(0, _anchor.y));
Mat rowKernel, columnKernel;
/**
在CV_32F, sdepth, ddepth中找到最大值并赋值给bdepth
bdepth: 位深度
*/
int bdepth = std::max(CV_32F,std::max(sdepth, ddepth));
int bits = 0;
/**
判断如果
输入输出图像都是8位无符号型且内核使用平滑对称核
或者
输出图像为16位有符号型且使用整形对称或反对称核
那么就不需要进行任何转换便可以直接使用,
否则便需要转换,因为输入前后的图像格式是完全相等的
所以delta就默认是0了
*/
if( sdepth == CV_8U &&
(
(rtype == KERNEL_SMOOTH+KERNEL_SYMMETRICAL &&
ctype == KERNEL_SMOOTH+KERNEL_SYMMETRICAL &&
ddepth == CV_8U)
||
(
(rtype & (KERNEL_SYMMETRICAL+KERNEL_ASYMMETRICAL)) &&
(ctype & (KERNEL_SYMMETRICAL+KERNEL_ASYMMETRICAL)) &&
(rtype & ctype & KERNEL_INTEGER) &&
ddepth == CV_16S
)
)
)
{
// 重新给bdepth赋值
bdepth = CV_32S;
// 此时bits(单位字节)将根据位深度进行计算,如果是8位无符号型则直接赋值为8位
bits = ddepth == CV_8U ? 8 : 0;
// 此时将row内核转换为CV_32S,即32位整数型,并且根据单位字节转换比例因子
// 如果不加比例因子那么图像会变得很白
// (可参见这篇提问https://bbs.csdn.net/topics/392411554)
// 比例因子:将原矩阵的所有元素乘以alpha
_rowKernel.convertTo( rowKernel, CV_32S, 1 << bits );
_columnKernel.convertTo( columnKernel, CV_32S, 1 << bits );
// 在这里是将单位字节*2
bits *= 2;
// 根据单位字节计算出了存储单位(偏移量)
_delta *= (1 << bits);
}
else
{
/**
如果不属于上面if里的任何一种情况,那么需要进行转换,用以使数据类型统一
*/
if( _rowKernel.type() != bdepth )
_rowKernel.convertTo( rowKernel, bdepth );
else
rowKernel = _rowKernel;
if( _columnKernel.type() != bdepth )
_columnKernel.convertTo( columnKernel, bdepth );
else
columnKernel = _columnKernel;
}
// 缓冲区存储,用于写入单个色所有素信息(包括多通道与深度信息)
int _bufType = CV_MAKETYPE(bdepth, cn);
// getLinearRowFilter是根据不同的输入图像类型,输出图像返回不同的线性滤波器
Ptr<BaseRowFilter> _rowFilter = getLinearRowFilter(
_srcType, _bufType, rowKernel, _anchor.x, rtype);
Ptr<BaseColumnFilter> _columnFilter = getLinearColumnFilter(
_bufType, _dstType, columnKernel, _anchor.y, ctype, _delta, bits );
// 利用这两个线性滤波器建立滤波引擎
return Ptr<FilterEngine>( new FilterEngine(Ptr<BaseFilter>(), _rowFilter,
_columnFilter,_srcType, _dstType,
_bufType, _rowBorderType,
_columnBorderType, _borderValue ));
}
/**
建立滤波引擎函数
*/
FilterEngine::FilterEngine( const Ptr<BaseFilter>& _filter2D,
const Ptr<BaseRowFilter>& _rowFilter,
const Ptr<BaseColumnFilter>& _columnFilter,
int _srcType, int _dstType, int _bufType,
int _rowBorderType, int _columnBorderType,
const Scalar& _borderValue )
{
init(_filter2D, _rowFilter, _columnFilter, _srcType, _dstType, _bufType,
_rowBorderType, _columnBorderType, _borderValue);
}
void FilterEngine::init( const Ptr<BaseFilter>& _filter2D,
const Ptr<BaseRowFilter>& _rowFilter,
const Ptr<BaseColumnFilter>& _columnFilter,
int _srcType, int _dstType, int _bufType,
int _rowBorderType, int _columnBorderType,
const Scalar& _borderValue )
{
// 依旧是获取类型
_srcType = CV_MAT_TYPE(_srcType);
_bufType = CV_MAT_TYPE(_bufType);
_dstType = CV_MAT_TYPE(_dstType);
// 临时变量
srcType = _srcType;
// 计算单个像素大小
// 下面会降解
int srcElemSize = (int)getElemSize(srcType);
// 下面这些全是建立临时变量的
dstType = _dstType;
bufType = _bufType;
filter2D = _filter2D;
rowFilter = _rowFilter;
columnFilter = _columnFilter;
// 这里是判断行列边缘类型是否出问题
if( _columnBorderType < 0 )
_columnBorderType = _rowBorderType;
rowBorderType = _rowBorderType;
columnBorderType = _columnBorderType;
// 检测边界填充类型是否不是wrap(复制元素填充)类型
CV_Assert( columnBorderType != BORDER_WRAP );
// 检测是否为可分离滤波器(因为这个是通用滤波引擎 并不知道是否为可分离滤波器)
if( isSeparable() )
{
// 检测横纵滤波器类型是否相等
CV_Assert( rowFilter && columnFilter );
// 并以横纵滤波器定义内核大小
ksize = Size(rowFilter->ksize, columnFilter->ksize);
// 锚点也根据滤波器锚点定义
anchor = Point(rowFilter->anchor, columnFilter->anchor);
}
else
{
// 如果不是 检测缓冲图像类型是否与输入图像类型相等
CV_Assert( bufType == srcType );
// 这里跟上面定义差不多,不过是非分离滤波器所以是只有一个(filter2D二维滤波器)
ksize = filter2D->ksize;
anchor = filter2D->anchor;
}
// 这个一看就懂了
CV_Assert( m 0 <= anchor.x && anchor.x < ksize.width &&
0 <= anchor.y && anchor.y < ksize.height );
// 根据边缘填充类型进行像素计算
borderElemSize = srcElemSize/(CV_MAT_DEPTH(srcType) >= CV_32S ?
sizeof(int) : 1);
// 这里也很好懂
int borderLength = std::max(ksize.width - 1, 1);
// 重定义边缘向量大小(这里是所占空间大小)
borderTab.resize(borderLength*borderElemSize);
// 初始化
maxWidth = bufStep = 0;
constBorderRow.clear();
// 如果行列边界是常数填充的
if( rowBorderType == BORDER_CONSTANT || columnBorderType == BORDER_CONSTANT )
{
// 则计算图像边长
constBorderValue.resize(srcElemSize*borderLength);
int srcType1 = CV_MAKETYPE(CV_MAT_DEPTH(srcType),
MIN(CV_MAT_CN(srcType),
4));
// 根据位深度将边界像素值转换成可直接使用的vector变量
scalarToRawData(_borderValue, &constBorderValue[0], srcType1,
borderLength*CV_MAT_CN(srcType));
}
// 初始化size
wholeSize = Size(-1,-1);
}
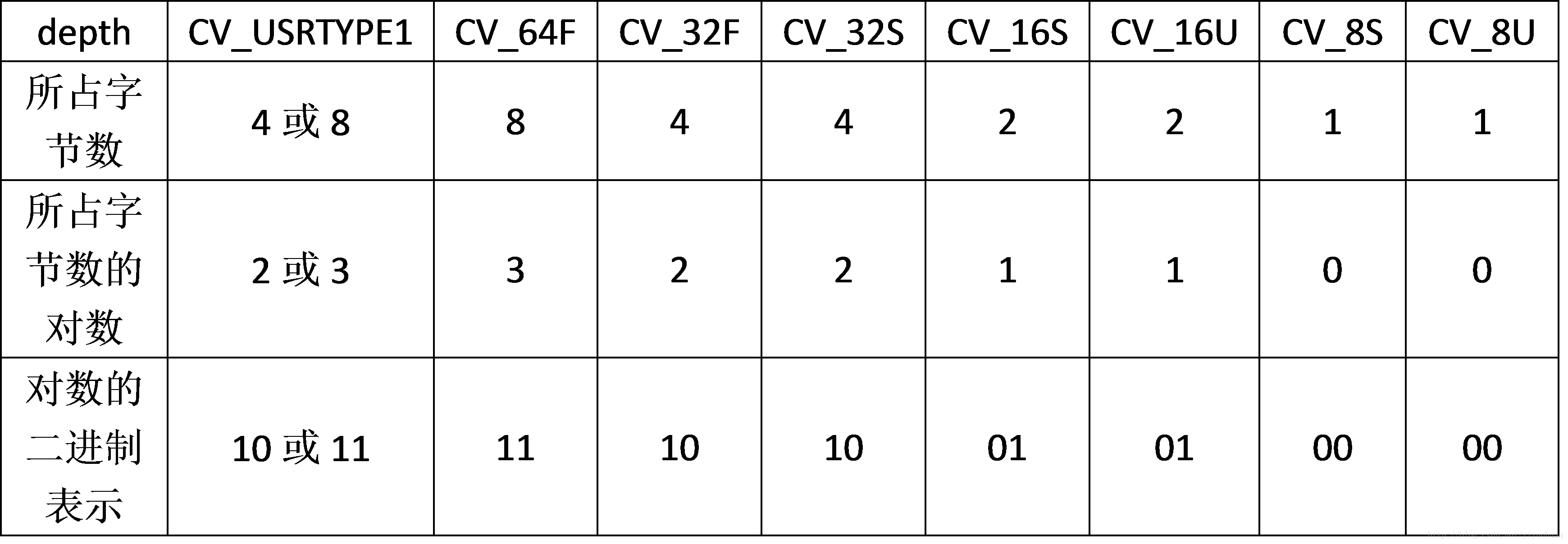
我们这时候来看上面提到的getElemSize:
最终这个其实是个宏定义,返回的就是这个宏定义计算的结果:
*(CV_MAT_CN(type) << ((((sizeof(size_t)/4+1)*16384|0x3a50) >> CV_MAT_DEPTH(type)2) & 3))
首先,针对
0x3a50这个奇怪的数值,我们先转换为2进制查看规律,通过查找比对,发现其数值与变量类型有着一一对应的关系,然后16384则是1 << 14的结果(刚好每个对应两位二进制数值),这个换成二进制则是 16384 = 10 00 00 00 00 00 00
0x3a50 = 11 10 10 01 01 00 00
稍微先理解一下,在下先说一下剩下的函数然后一起解析。
这里先计算无符号整型的长度(在64位系统下是4 desu)然后除以4 再加上1 ,
就是说这是2 * 16384 | 0x3a50
就是
01 00 00 00 00 00 00 00
00 11 10 10 01 01 00 00
01 11 10 10 01 01 00 00
的结果右移2 * 深度,观察上面便会发现最终右移之后便使得最后两位二进制数对应的刚好便是对应变量类型所占的二进制数。
这样,在跟3(二进制为11)进行 ‘与‘ 操作,便能得到各个变量的对应所占字节数的对数了。
又因为这里是 通道数 * 2 ^ (所占字节对数)
所以这样就能够计算的出单个像素点所占用的大小(size)了
因为滤波引擎是一个通用引擎,还可用以驱动其他的滤波器(中值滤波或者其他什么的)所以主要的就只不过是根据一些信息初始化用以后面的操作(就是init函数的意思)。
返回了滤波引擎之后便是调用了,这个是apply函数:
c++void FilterEngine::apply(const Mat& src, Mat& dst, const Size & wsz, const Point & ofs)
{
CV_INSTRUMENT_REGION()
CV_Assert( src.type() == srcType && dst.type() == dstType );
// 返回变化y值
int y = start(src, wsz, ofs);
// 传参的时候切除第一行与最后一列
proceed(src.ptr() + y*src.step,
(int)src.step,
endY - startY,
dst.ptr(),
(int)dst.step );
}
其中start便是开始函数后面的proceed则是持续卷积到整个图像的关键,start函数最终返回了起始的Y值,一句一句写太累了,我就不解释了,只贴出start与proceed函数:
**这两块其实在下分析的很差,很多函数都没看懂,有很大可能错误,建议先跳过,在下以后c++学透了还会回来改的。 **
c++/**
滤波引擎
发动!
*/
int FilterEngine::start(const Mat& src, const Size &wsz, const Point &ofs)
{
start( wsz, src.size(), ofs);
return startY - ofs.y;
}
int FilterEngine::start(const Size &_wholeSize, const Size &sz, const Point &ofs)
{
int i, j;
wholeSize = _wholeSize;
// 根据偏移量与矩阵头设置范围
roi = Rect(ofs, sz);
// 依旧是错误检测,很好懂
CV_Assert( roi.x >= 0 && roi.y >= 0 && roi.width >= 0 && roi.height >= 0 && roi.x + roi.width <= wholeSize.width && roi.y + roi.height <= wholeSize.height );
// 下面这些依旧是初始化
int esz = (int)getElemSize(srcType);
int bufElemSize = (int)getElemSize(bufType);
// 定值检查
const uchar* constVal = !constBorderValue.empty() ? &constBorderValue[0] : 0;
int _maxBufRows = std::max(ksize.height + 3, std::max(anchor.y, ksize.height-anchor.y-1)*2+1);
if( maxWidth < roi.width || _maxBufRows != (int)rows.size() )
{
rows.resize(_maxBufRows);
maxWidth = std::max(maxWidth, roi.width);
int cn = CV_MAT_CN(srcType);
srcRow.resize(esz*(maxWidth + ksize.width - 1));
if( columnBorderType == BORDER_CONSTANT )
{
constBorderRow.resize(getElemSize(bufType)
*(maxWidth + ksize.width - 1 + VEC_ALIGN));
uchar *dst = alignPtr(&constBorderRow[0], VEC_ALIGN), *tdst;
int n = (int)constBorderValue.size(), N;
N = (maxWidth + ksize.width - 1)*esz;
tdst = isSeparable() ? &srcRow[0] : dst;
for( i = 0; i < N; i += n )
{
n = std::min( n, N - i );
for(j = 0; j < n; j++)
tdst[i+j] = constVal[j];
}
if( isSeparable() )
(*rowFilter)(&srcRow[0], dst, maxWidth, cn);
}
int maxBufStep = bufElemSize*(int)alignSize(maxWidth + (!isSeparable() ? ksize.width - 1 : 0),VEC_ALIGN);
ringBuf.resize(maxBufStep*rows.size()+VEC_ALIGN);
}
// 调整bufstep,使环形缓冲区的已使用部分在内存中保持紧凑
bufStep = bufElemSize*(int)alignSize(roi.width + (!isSeparable() ? ksize.width - 1 : 0),16);
// dx1是检测锚点位置是否与范围边界检测
dx1 = std::max(anchor.x - roi.x, 0);
// 检测内核是否存在偏差
dx2 = std::max(ksize.width - anchor.x - 1 + roi.x + roi.width - wholeSize.width, 0);
// 如果存在偏差则重新计算边界表
if( dx1 > 0 || dx2 > 0 )
{
if( rowBorderType == BORDER_CONSTANT )
{
int nr = isSeparable() ? 1 : (int)rows.size();
for( i = 0; i < nr; i++ )
{
uchar* dst = isSeparable() ? &srcRow[0] : alignPtr(&ringBuf[0],VEC_ALIGN) + bufStep*i;
// 在内存中用后者填充前者,最后一个参数是大小
memcpy( dst, constVal, dx1*esz );
memcpy( dst + (roi.width + ksize.width - 1 - dx2)*esz, constVal, dx2*esz );
}
}
else
{
int xofs1 = std::min(roi.x, anchor.x) - roi.x;
int btab_esz = borderElemSize, wholeWidth = wholeSize.width;
int* btab = (int*)&borderTab[0];
for( i = 0; i < dx1; i++ )
{
int p0 = (borderInterpolate(i-dx1, wholeWidth, rowBorderType) + xofs1)*btab_esz;
for( j = 0; j < btab_esz; j++ )
btab[i*btab_esz + j] = p0 + j;
}
for( i = 0; i < dx2; i++ )
{
int p0 = (borderInterpolate(wholeWidth + i, wholeWidth, rowBorderType) + xofs1)*btab_esz;
for( j = 0; j < btab_esz; j++ )
btab[(i + dx1)*btab_esz + j] = p0 + j;
}
}
}
rowCount = dstY = 0;
/**
这整个函数其实最重要的就是这个
上面这些都是防止错误进行的调整
并用以计算下面这个值的
这个startY是另一方向的偏离值,就是说一个像素到另一个像素的偏离量
*/
startY = startY0 = std::max(roi.y - anchor.y, 0);
endY = std::min(roi.y + roi.height + ksize.height - anchor.y - 1, wholeSize.height);
if( columnFilter )
columnFilter->reset();
if( filter2D )
filter2D->reset();
return startY;
}
int FilterEngine::proceed( const uchar* src, int srcstep, int count,
uchar* dst, int dststep )
{
CV_Assert( wholeSize.width > 0 && wholeSize.height > 0 );
const int *btab = &borderTab[0];
int esz = (int)getElemSize(srcType), btab_esz = borderElemSize;
uchar** brows = &rows[0];
int bufRows = (int)rows.size();
int cn = CV_MAT_CN(bufType);
int width = roi.width, kwidth = ksize.width;
int kheight = ksize.height, ay = anchor.y;
int _dx1 = dx1, _dx2 = dx2;
int width1 = roi.width + kwidth - 1;
int xofs1 = std::min(roi.x, anchor.x);
// 是否分开
bool isSep = isSeparable();
bool makeBorder = (_dx1 > 0 || _dx2 > 0) && rowBorderType != BORDER_CONSTANT;
int dy = 0, i = 0;
src -= xofs1*esz;
count = std::min(count, remainingInputRows());
CV_Assert( src && dst && count > 0 );
/**
这里就是卷积的主函数了
*/
for(;; dst += dststep*i, dy += i)
{
int dcount = bufRows - ay - startY - rowCount + roi.y;
dcount = dcount > 0 ? dcount : bufRows - kheight + 1;
dcount = std::min(dcount, count);
count -= dcount;
for( ; dcount-- > 0; src += srcstep )
{
int bi = (startY - startY0 + rowCount) % bufRows;
uchar* brow = alignPtr(&ringBuf[0], VEC_ALIGN) + bi*bufStep;
uchar* row = isSep ? &srcRow[0] : brow;
if( ++rowCount > bufRows )
{
--rowCount;
++startY;
}
memcpy( row + _dx1*esz, src, (width1 - _dx2 - _dx1)*esz );
if( makeBorder )
{
if( btab_esz*(int)sizeof(int) == esz )
{
const int* isrc = (const int*)src;
int* irow = (int*)row;
for( i = 0; i < _dx1*btab_esz; i++ )
irow[i] = isrc[btab[i]];
for( i = 0; i < _dx2*btab_esz; i++ )
irow[i + (width1 - _dx2)*btab_esz] = isrc[btab[i+_dx1*btab_esz]];
}
else
{
for( i = 0; i < _dx1*esz; i++ )
row[i] = src[btab[i]];
for( i = 0; i < _dx2*esz; i++ )
row[i + (width1 - _dx2)*esz] = src[btab[i+_dx1*esz]];
}
}
if( isSep )
(*rowFilter)(row, brow, width, CV_MAT_CN(srcType));
}
int max_i = std::min(bufRows, roi.height - (dstY + dy) + (kheight - 1));
for( i = 0; i < max_i; i++ )
{
int srcY = borderInterpolate(dstY + dy + i + roi.y - ay, wholeSize.height, columnBorderType);
if( srcY < 0 ) // can happen only with constant border type
brows[i] = alignPtr(&constBorderRow[0], VEC_ALIGN);
else
{
CV_Assert( srcY >= startY );
if( srcY >= startY + rowCount )
break;
int bi = (srcY - startY0) % bufRows;
brows[i] = alignPtr(&ringBuf[0], VEC_ALIGN) + bi*bufStep;
}
}
if( i < kheight )
break;
i -= kheight - 1;
if( isSeparable() )
(*columnFilter)((const uchar**)brows, dst, dststep, i, roi.width*cn);
else
(*filter2D)((const uchar**)brows, dst, dststep, i, roi.width, cn);
}
dstY += dy;
CV_Assert( dstY <= roi.height );
return dy;
}
总结
- 优化不一定是自己算法的优化,还有使用平台的优化。
- 大型项目里面代码风格各异,变量命名方案比较混乱,并且简写的比较多,看起来真的头大。。。。
- 在下的代码逻辑思维还是太低了,希望能够在毕业的时候看上20000行代码用以提升自己。
借物表
- attribute 机制详解(一)
- What is this #ifdef GNUC about?
- 关于VC预定义常量_WIN32,WIN32,_WIN64等预定义宏的介绍(整理、转载)
- opencv的CV_EXPORT
- 图像处理基础(4):高斯滤波器详解
- C/C++ 可变参数宏与__VA_ARGS__ 宏
- #、##、__VA_ARGS__和##__VA_ARGS__的作用
- OpenVX嵌入式图像处理(一)硬件平台及软件介绍
- OpenCV3.x中UMat对象介绍与使用
- opencv学习之GaussianBlur()源码解析
- 手撕OpenCV源码之GaussianBlur
- OpenCV的一些宏
感谢以上各位大佬给在下提供的各类知识


本文作者:xmmmmmovo
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 许可协议。转载请注明出处!